Ceph集群IO提交延迟统计跳变问题分析

Contents
问题现象
- 环境:Ceph集群节点异常重启后
- 异常指标:
ceph_osd_op_w_latency的Prometheus rate值 - 具体表现:
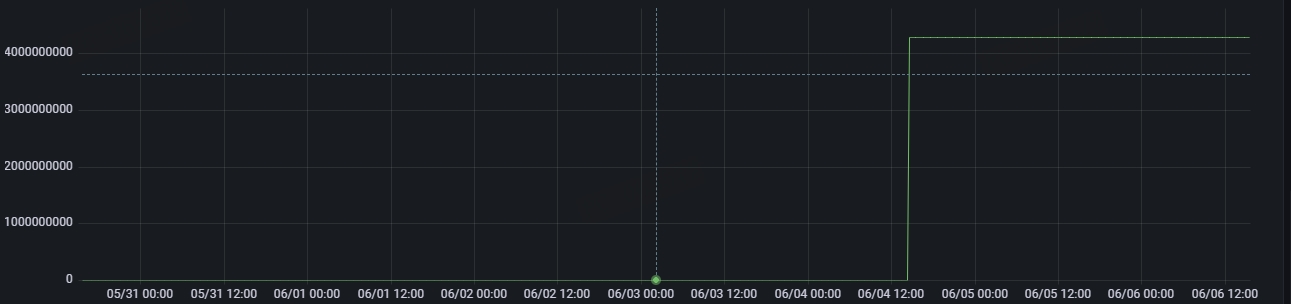
- 重启前:数值正常递增(峰值约1M)
- 重启后:从0开始记录,3分钟后突增至42亿(接近2³²)
排查过程
第一阶段:初始假设
| 假设方向 | 验证方法 | 结论 |
|---|---|---|
| Prometheus计算问题 | 检查rate()函数逻辑 | 确认已处理计数器归零情况 |
| Ceph统计初始化问题 | 审查OSD.cc初始化代码 | 确认atomic变量正确初始化 |
第二阶段:深度分析
- 关键发现:
- 跳变前存在3分钟归零期
- 42亿跳变值导致坐标轴显示异常
- 机制分析:
- 使用系统实时时钟计算时间差
- 无负值保护机制
第三阶段:验证
- 环境证据:
- NTP日志显示4ms时间回退

- 复现方法:
- 通过fio施加IO负载
- 手动回拨系统时间1ms
- 成功复现跳变现象
根因结论
- 直接原因:
- 系统时间回拨导致负时间差
- 无符号整数存储转换
- 深层原因:
- 未全面采用单调时钟
- 相关PR #39273 https://github.com/ceph/ceph/pull/39273 没有修改全部的realtime
解决方案
- 长期改进:
- 推动monotonic时钟全面替换
- 或者增加时间差值校验逻辑
- 在官方 slack 提了一个 issue https://tracker.ceph.com/issues/71580,目前官方已跟进修改 https://github.com/ceph/ceph/pull/64003。
Author ceph-deep-dive
LastMod 2025-06-10