Thinking about 3FS

Contents
Rise to Prominence: 3FS
In the past two months, DeepSeek’s popularity has skyrocketed. What particularly delights us storage professionals is that DeepSeek has brought distributed storage, which has long been hidden away, to the forefront. The GitHub attention that 3FS has received is unprecedented among open-source distributed storage projects, and there probably won’t be another like it. The star count in just 3 days after open-sourcing exceeded that of numerous open-source storage projects that have been cultivating for years. Social media and various technical discussion groups are filled with discussions about 3FS. So I’m also jumping on the bandwagon, though I mainly don’t want to discuss 3FS itself, but rather discuss the storage behind large models and the storage systems I actually use frequently in AI applications. After all, there are already many technical articles discussing 3FS, and with such excellent predecessors, I won’t embarrass myself.
- DeepSeek 3FS: End-to-End Cacheless Storage New Paradigm
- Real Test of DeepSeek 3FS: We Disassembled the Violent Aesthetics of the Performance Monster
- Deepseek 3FS (Fire-Flyer File System) Design Notes
- Real Testing of DeepSeek Open Source 3FS Based on eRDMA
- DeepSeek 3FS Interpretation and Source Code Analysis (1): The Way of Efficient Training
What Kind of Storage Does AI Need?
This is actually an age-old question, and there are many high-quality articles online. However, there seems to be little content that connects AI and storage step by step (maybe I just haven’t found the relevant content, but it doesn’t matter, organizing this article is mainly to help myself sort out knowledge in this area). Let’s set this aside for now and expand on it step by step later.
AI Training Framework + Storage Integration
When discussing AI storage, we can’t avoid AI training frameworks. Storage has always been just a castle in the air - without OpenStack, without Kubernetes, without AI training frameworks, storage cannot be implemented.
Current mainstream AI training frameworks include PyTorch, TensorFlow, and PaddlePaddle. Here we use PyTorch as an example. PyTorch provides two data primitives: torch.utils.data.Dataset and torch.utils.data.DataLoader. PyTorch data loading is completed through Dataset+DataLoader, where Dataset defines the data format and data transformation forms, and DataLoader continuously reads batch data in an iterative manner.
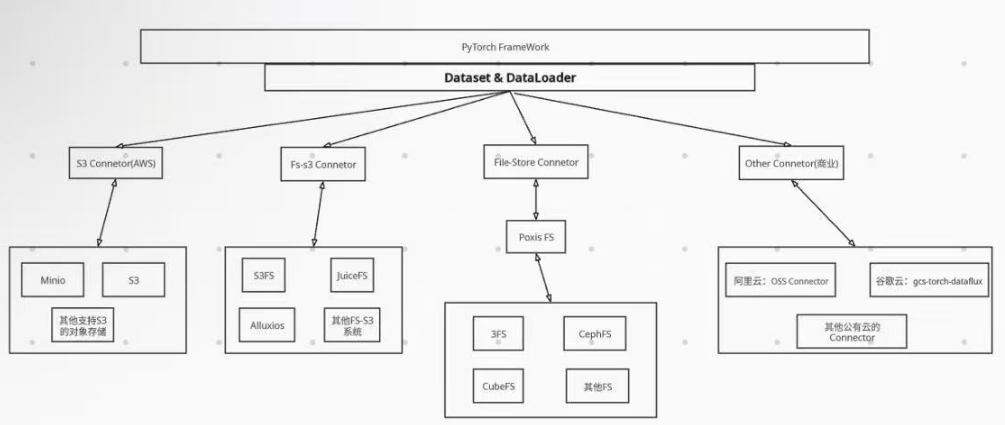
You can implement flexible data reading by inheriting PyTorch’s own Dataset class. Various systems can implement data connections (Connectors) with PyTorch based on this.
The following shows the overall framework diagram. The S3 Connector and FS-S3 Connector shown below are both developed by AWS (details can be found in aws-connector-for-pytorch). The Amazon S3 Connector for PyTorch automatically optimizes S3 read and list requests to improve data loading and checkpoint performance for training workloads. Due to S3’s universality, object storage systems that support S3 can directly use the Amazon S3 Connector for PyTorch. FS-S3 uses S3 at the bottom layer and can be exported through the file system, which is also a popular type of system currently, combining the advantages of both fs and s3. File-Store Connector is the system that PyTorch supports by default. In addition to these, there are also some public cloud’s own Connectors.
- AWS S3 Connector Usage Example
|
|
- File-Store Connector Usage Example File-Store Connector is the system that PyTorch supports by default, used as follows:
|
|
- Alibaba Cloud OSS Connector Usage Example
|
|
AI Training Phases and Storage Requirements
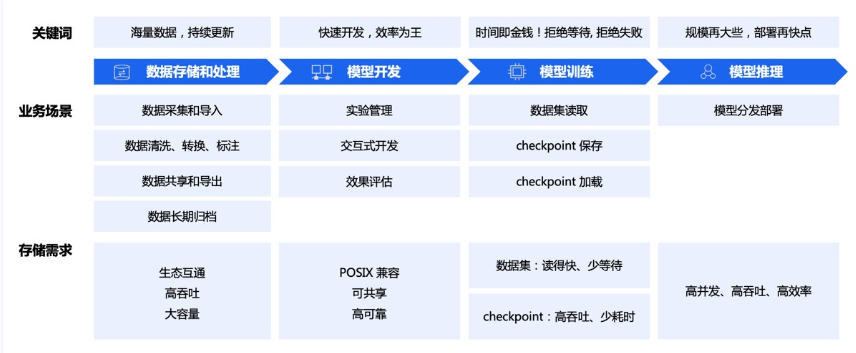
AI training mainly includes data collection & preprocessing storage; model development; model training; model inference phases. The general storage requirements for each phase are as follows. This Baidu article provides a good introduction to this phase
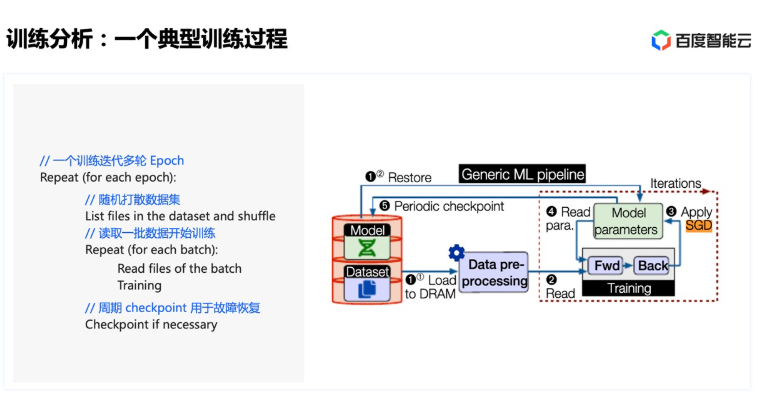
 Here we focus on the relationship between training and storage: For training, there may be multiple iterations (epochs). Within each epoch, the dataset first needs to be shuffled randomly, then the shuffled data is divided into several batches. Each time a batch of data is read, one training iteration is performed. Checkpoints are also saved periodically for fast failure recovery:
Here we focus on the relationship between training and storage: For training, there may be multiple iterations (epochs). Within each epoch, the dataset first needs to be shuffled randomly, then the shuffled data is divided into several batches. Each time a batch of data is read, one training iteration is performed. Checkpoints are also saved periodically for fast failure recovery:
 So the storage requirements for AI training are roughly as follows:
So the storage requirements for AI training are roughly as follows:
- The shuffle phase is a pure metadata operation process:
Main file system metadata requests include readdir + getattr:
- Get dentry metadata information of subdirectories through readdir
- Then get the file’s inode through getattr, which can then be used to read and write files
- The data reading process mainly tests the storage system’s read capability
- CheckPoint: A single node’s checkpoint for large models can typically reach tens to hundreds of GB. Multiple training nodes write simultaneously, and need to read simultaneously when recovering. Since Checkpoint is a single large file (each GPU has one CheckPoint under parallel GPU training), when writing CheckPoint, the storage system’s write bandwidth capability is required; when recovering, the storage system’s read bandwidth capability is required. So for AI training, random write capability for small files is not the most important. The most important are the storage system’s metadata processing capability, read-write bandwidth capability, or read IOPS capability (if the training model involves a large number of small files).
AI and CephFS
Advantages of CephFS in AI Applications
- Bandwidth Capability Ceph’s underlying storage engine, compared to other Raft-based distributed storage systems, doesn’t have the double-write problem (AI scenarios involve large writes), thus providing excellent data bandwidth capability.
- Linear Scaling Ceph provides excellent linear scaling capability for both capacity and performance. A single cluster can support tens of thousands of hard drives.
- Stability After all these years, Ceph’s stability is quite reliable. A cluster can sit there for months without management and probably won’t have any problems (of course, don’t mess around with it).
- Maintainability Ceph supports Prometheus, Grafana, and has a web console. Ceph has also developed numerous metrics and tools.
- Functionality Nothing more to say, it’s all about being comprehensive.
- Strong Consistency Provides multi-write capability for the same file. This might be its biggest feature compared to other distributed file systems on the market, as most file systems only support CTO (close to open semantics). Of course, this strong consistency also brings disadvantages, which we’ll discuss below.
- Supports both kernel and FUSE modes Most other open-source file systems are FUSE-based.
CephFS Disadvantages
- Metadata Consistency Issues & Lock Problems Ceph’s strong consistency may bring serious metadata performance issues. For example: if Client A is currently writing a file (it holds the write buffer cap for this file), and Client B also wants to access this file, then to ensure data consistency, MDS will require Client A to flush all its write buffers to the underlying data pool. If the write buffer data is large, or if the network capability between Client A and backend storage is not particularly good, this flush time may be quite long. During this process, A is always waiting for locks, which is a classic type of metadata performance issue in CephFS. We often see alerts like “fail to lock”.
- MDS Single-threaded Problem MDS processes IO in a single thread, and all metadata requests from clients are first placed in a queue and processed one by one.
- Metadata Scalability Issues Metadata cannot scale linearly. Current newer generation file systems, such as CubeFS, Alibaba’s InitFS, Baidu’s CFS, etc., all have metadata clusters that can scale linearly. Although CephFS can use multiple MDS, the dynamic balancing of multiple MDS doesn’t seem very stable yet. Generally, manual pinning is used, which increases operational complexity.
- High Latency for Small Write IOPS in Data Operations Due to the long chain on the OSD side, as well as locks, including BlueStore single-threaded flush and other reasons, the latency of individual IOs cannot be very low. Of course, in AI scenarios, small write latency is not a very important metric.
- High Difficulty No explanation needed, those who understand will understand.
Possible CephFS Optimizations
- Use multiple MDS
- Try to use cache (MDS cache & OSD cache)
- Deploy MDS and metadata pool OSDs on the same machine
- Consider using lazyio functionality
- Reduce small file operations: preprocess data into formats like TFRecords
Typical AI Storage Systems
| Storage Type | Representative Systems |
|---|---|
| Local File System | NVME + Local File System (xfs, ext4, zfs, etc.) |
| Distributed File System | 3FS, CephFS, DAOS, CubeFS, Lustre |
| Object Storage | Minio, S3, NVIDIA/Aistore |
| File Gateway + Object Storage | JuiceFS, Alluxio, CurveFS |
| Vector Database | Milvus |
| Commercial Storage | VAST DATA, WeakFS, YRCloudFile, Baidu Canghai CFS |
Current Status of 3FS
3FS is really hot. Finally, let me briefly describe the current status of 3FS that I know of around me: companies like Ant Group, Xiaohongshu, ByteDance, China Unicom, etc. are all actively preparing environments for real testing.
Author ceph-deep-dive
LastMod 2025-05-30