3FS的一点思考

Contents
横空出世: 3FS
近两个月,DeepSeek的热度值爆表。尤其令我们存储人欣喜的是,DeepSeek竟然把一向养在深闺无人识的分布式存储推到了台前。 3FS的github关注度之大,在开源分布式存储项目算是前无古人了,估计也很难有来者。 开源3天的star数就超过了一众已经耕耘数年的开源存储项目。朋友圈和各个技术交流群里也到处都是谈论3FS的声音。 所以也来蹭蹭热度,不过我主要不是想讨论3FS,而是想讨论讨论大模型背后的存储以及本人实际用的比较多的存储系统在AI这块的应用。毕竟讨论3FS的技术文章已经很多了,珠玉在前,就不献丑了。
- DeepSeek 3FS:端到端无缓存的存储新范式
- 实测 DeepSeek 3FS:我们拆解了性能怪兽的暴力美学
- Deepseek 3FS( Fire-Flyer File System)设计笔记
- 基于eRDMA实测DeepSeek开源的3FS
- DeepSeek 3FS解读与源码分析(1):高效训练之道
AI 需要什么样的存储?
其实这也是一个老生常谈的问题,网上也有很多质量非常高的文章。但是好像鲜有把AI和存储一步一步串联起来的内容(可能是我自己没找到相关内容,不过不重要,整理这篇文章也主要是为了让自己对这一块知识有一个梳理)。这里先按下不表,后续一步一步展开。
AI训练框架 + 存储结合
聊AI存储,首先就离不开AI训练框架。存储从来都只是空中楼阁,没有openstack,没有k8s,没有AI训练框架,那么存储就没办法落地。
当前主流的AI训练框架有PyTorch,TensorFlow,PaddlePaddle
我们这里以PyTorch为例,PyTorch中提供了两个数据原语:torch.utils.data.Datase和torch.utils.data.DataLoader。PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
可以通过继承PyTorch自身的Dataset类,来实现灵活的数据读取。各个系统可以基于此实现数据与PyTorch的连接(Connector)。
如下展示了整体框架图。其中如下的S3 Connector和FS-S3 Connector都是是AWS 开发的(详情可见aws-connector-for-pytorch)。适用于 PyTorch 的 Amazon S3 Connector for PyTorch 会自动优化 S3 读取和列出请求,以改善训练工作负载的数据加载和检查点性能,由于S3的通用性,所以支持S3的对象存储系统都可以直接使用 Amazon S3 Connector for PyTorch。Fs-S3 的话就是底层使用的是S3,然后可以通过文件系统导出,这也是目前比较流行的一类系统,这类系统兼具了fs和s3的优势。File-Store Connector是PyTorch默认支持的系统。除了这些,还有一些公有云自己的Connector。
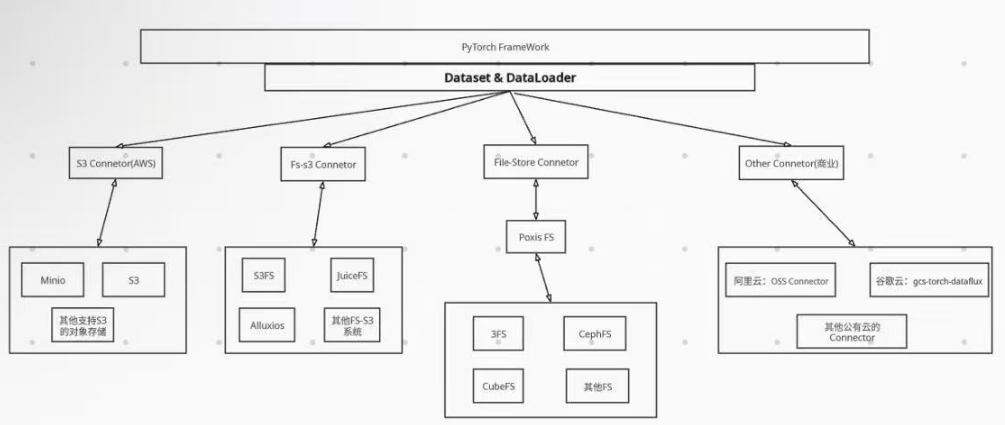
- AWS S3 Connector的使用实例
|
|
- File-Store Connector的使用实例 File-Store Connector是PyTorch默认支持的系统,使用如下:
|
|
- 阿里云 oss Connector的使用实例
|
|
AI训练阶段及存储需求
AI训练主要有数据采集&预处理存储 ; 模型开发 ;模型训练 ;模型推理几个阶段;各个阶段大致的存储需求如下,这个阶段的内容百度这篇文章介绍很好
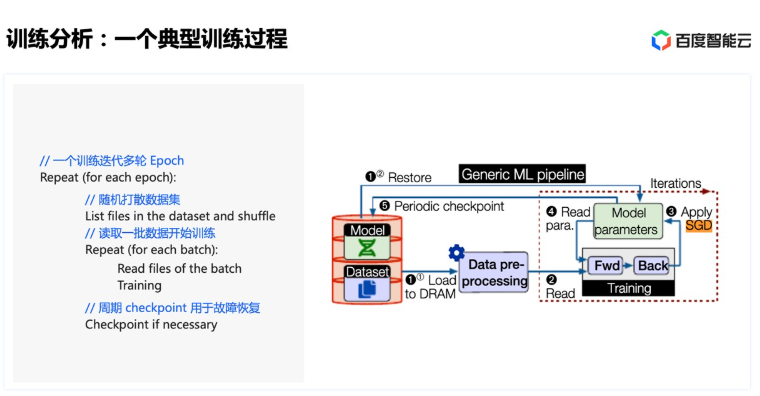
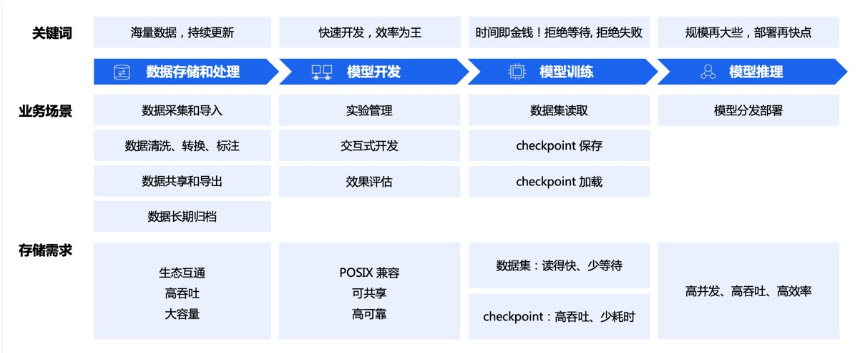 这里重点说下训练和存储的关系:对于训练来说,可能迭代多轮(epoch)。在每个 epoch 内,首先需要对数据集进行shuffle随机打散,然后将打散后的数据划分为若干 batch,每读取一个 batch 的数据,进行一次训练迭代。同时会周期性保存 checkpoint 用于故障快速恢复:
这里重点说下训练和存储的关系:对于训练来说,可能迭代多轮(epoch)。在每个 epoch 内,首先需要对数据集进行shuffle随机打散,然后将打散后的数据划分为若干 batch,每读取一个 batch 的数据,进行一次训练迭代。同时会周期性保存 checkpoint 用于故障快速恢复:
 所以AI训练对存储的需求大致如下:
所以AI训练对存储的需求大致如下:
- shuffle阶段是纯元数据操作的过程: 主要文件系统元数据请求包括readdir + getattr:
- 通过readdir获取到目录下面子文件的dentry元数据信息
- 然后通过getattr获取到文件的inode,进而就可以基于此对文件进行读写了
- 数据读取过程则主要考验的是存储系统的读能力了
- CheckPoint:大模型单个节点的 checkpoint 通常就能达到几十上百 GB。而多个训练节点同时写,需要恢复时又同时读。 由于Checkpoint是单个的大文件(并行GPU训练下每个GPU都有一个CheckPoiunt),所以当写CheckPoint时,要求的是存储系统的写带宽能力;而当恢复时,要求的是存储系统的读带宽能力 所以对于AI训练来说,小文件的随机写能力不是最重要的,最重要的还是存储系统的元数据处理能力,以及读写带宽能力,或者是读iops能力(如果训练模型是大量小文件)
AI与CephFS
CephFS应用在AI优点
- 带宽能力 Ceph的底层存储引擎与其他基于Raft的分布式存储相比,不存在双写问题(AI场景是大写),故而有优秀的数据带宽能力。
- 线性扩展 Ceph提供了非常好的容量以及性能线性扩展能力。单集群可以支持上万块硬盘。
- 稳定性 Ceph经历了这么多年,稳定性还是很有保障的,一个集群放在那里,几个月没人管可能都没什么问题(当然,不要瞎折腾)。
- 可运维性 Ceph支持Promethus,Geafana,又有web控制台。同时Ceph开发了大量metric以及工具。
- 功能 这个啥也不说,主打一个大而全。
- 强一致性 提供同一文件的多写能力。这可能是它相比市面上其他分布式文件系统最大的特色了,一般文件系统都只支持CTO(close to open语义) 当然,这种强一致性也会带来缺点,下面会聊到。
- 支持kernel态 + fuse态两种形态 大部分其他开源文件系统都是基于fuse的
CephFS缺点
- 元数据的一致性问题 & 锁问题 Ceph的强一致性可能会带来比较严重的元数据性能问题。举个例子:A Client此时正在写某个文件(它持有这个文件的写buffer cap),如果此时B client也要访问该文件,那么为了保证数据的一致性,mds此时会要求A client把它的写buffer全部flush刷到底层数据池子去,如果写buffer数据量比较多,或者是A client和后端存储网络能力此时不是特别好,那么这个flush时间可能会比较长,这个过程A一直在锁等待,这就是CephFS里比较经典的一类元数据性能问题,我们经常会看到类似“fail to lock”这类的告警。
- MDS的单线程问题 MDS处理io是一个单线程,收到的所有Client的元数据请求都会先放在队列里面,一个个排队处理。
- 元数据扩展性问题 元数据无法线性扩展,当前较新一代的文件系统,比如cubefs,阿里的initfs, 百度的cfs等,元数据都是一个元数据集群,该集群可以线性扩展。 虽然CephFS可以采用多mds,但是多mds的动态均衡貌似还不是很稳定。一般使用都是手工pin,这增加了运维的复杂度。
- 数据操作的小写iops时延较高 由于osd侧的链路太长,以及锁,包括BlueStore单线程flush等原因,单个io的时延没法做到很低。当然,在AI场景下,小写时延不是非常重要的一个指标。
- 难度过高 这个不解释,懂的都懂
CephFS可能的优化
- 使用多mds
- 尽量使用cache(mds cache & osd cache)
- MDS和元数据池子osd部署在同一机器
- 可以考虑使用lazyio功能
- 减少小文件操作:将数据预处理为类似TFRecords这样的格式
典型AI存储系统
| 存储类型 | 代表性系统 |
|---|---|
| 本地文件系统 | NVME + 本地文件系统(xfs, ext4, zfs等) |
| 分布式文件系统 | 3FS, CephFS, DAOS, CubeFS, Lustre |
| 对象存储 | Minio, S3, NVIDIA/Aistore |
| 文件网关+对象存储 | JuiceFS, Alluxio, CurveFS |
| 向量数据库 | Milvus |
| 商业存储 | VAST DATA, WeakFS, YRCloudFile, 百度沧海CFS |
3FS 现状
3FS实在是火,最后简单描述下我了解到的身边关于3FS的一些现状:蚂蚁,小红书,字节,中国联通等公司都在积极准备环境实测。
Author ceph-deep-dive
LastMod 2025-05-30